
Napadlo vás někdy, že byste chtěli mít vlastní malý Google Translate přímo ve svém počítači? Který by se naučil překládat podle vašich překladů a kterému byste mohli svěřit i citlivé texty, které nesmí opustit váš stroj? S programem Slate Desktop™ tuto možnost máte.
Strojové překladače, jako je ten od Googlu nebo Microsoftu, někteří překladatelé používají k tomu, aby získali polotovar, a ten upraví k obrazu svému. U některých typů textů jsou výsledky celkem dobré a můžou práci podstatně usnadnit. Často ovšem pracujeme s citlivými dokumenty, které náš počítač nesmí opustit. A není koneckonců citlivý skoro každý text? Nemusí nutně obsahovat důvěrné informace, třeba je ale autorským dílem nebo by zkrátka pro klienta nemuselo být příjemné, kdyby zjistil, že se jeho text ocitl na cizím serveru mimo jeho kontrolu.
Nabízí se proto otázka, jestli neexistuje program, který by se nainstaloval do počítače a uměl něco podobného jako veřejné překladače, aniž by cokoli kamkoli odesílal. Když jsem začal hledat odpověď na tuto otázku, myslel jsem si, že podobných nástrojů bude celá plejáda, ale mýlil jsem se. Je jich jen hrstka, mnohdy nepodporují češtinu a především… některé běží opět kdesi v cloudu, takže mé základní kritérium nesplňovaly. Jejich provozovatelům sice můžete věřit, že jsou vaše data v bezpečí, ale možná máte s klientem podepsanou smlouvu, která vám něco takového výslovně zakazuje. Další problém je často v cenové politice: někteří z provozovatelů si účtují měsíční poplatky, které sice možná na první pohled vypadají příznivě, ale během několika let se můžou nasčítat tak, že se nestačíte divit a litujete, že jste si raději nevybrali řešení, které by se zaplatilo jednorázově a sloužilo by vám bez časového omezení.
Potom jsem našel několik nástrojů, které jsou sice zadarmo, ale vyžadují velmi pokročilé znalosti v oblasti IT a složitou manipulaci s daty. Tato řešení jsem zavrhl, protože to není nic pro běžného překladatele. Program, který moje kritéria splňoval, jsem ale nakonec přece jen našel. Jmenuje se Slate Desktop™, vytvořila jej společnost Precision Translation Tools a skutečně běží přímo ve vašem počítači, a to buď ve Windows, nebo v Linuxu. Podporuje 32 jazyků včetně češtiny a většiny ostatních jazyků EU. Program můžete používat buď samostatně, nebo prostřednictvím některého z podporovaných CAT nástrojů. Pro informované dodám, že v jeho jádru je systém Moses.
Minimální požadavky na hardware a software:
- čtyřjádrový procesor x86-64/x64 s frekvencí nejméně 2,5 GHz – Intel Core i3 (ale ideálně i7), AMD Athlon 64
- RAM 4 GB (ideálně však 8 GB a více)
- 2 GB volného místa na pevném disku během instalace
- 40 GB volného místa na výkonném pevném disku po instalaci (ideálně 250 GB a více)
- operační systém Windows (XP Professional, 7, 8, 10) nebo Linux (obojí x64) – podrobnosti zde
Podporované CAT nástroje:
- memoQ 2015 a novější
- SDL Trados Studio 2015 a 2017
- OmegaT
- CafeTran
Než program začnete používat, musíte ho „nakrmit“ pořádnými dávkami překladových pamětí – ideální jsou vaše vlastní paměti, ale můžete samozřejmě využít i paměti získané jinak. Tato fáze je výpočetně velmi náročná, takže ke zpracování osobních pamětí jednoho překladatele program potřebuje několik hodin – ideální je nechat počítač běžet přes noc. A potřebujete relativně dobře vybavený počítač – pryč jsou ty časy, kdy překladatelům stačil jeden z výkonnostně nejslabších strojů na trhu.
Video. Slate Desktop – Create A Translation Engine (anglicky)
„On mě napodobuje!“
Jakmile si Slate Desktop zpracuje paměti, je schopen na základě těchto dat generovat překlady. Když mu tedy dáte jako „učební materiál“ své vlastní paměti, napodobuje přímo vás a váš styl. Znamená to, že když upravujete (posteditujete) navrhované překlady k obrazu svému, máte s úpravou méně práce, než kdyby se program učil překládat z pamětí kolegy, který třeba rád a často používá slova neboť a třebaže a vy je bytostně nesnášíte.
Jak velké množství dat program potřebuje, aby předkládal smysluplné návrhy? Na to přesná odpověď neexistuje, protože záleží na jazykové kombinaci a typu textů, ale dobré zkušenosti jsou s paměťmi asi od 80 tisíc segmentů. To vůbec není málo, na druhou stranu mnoho překladatelů má i větší paměti. Nebo pracují v týmech, které paměti sdílejí, takže této kritické minimální velikosti dosáhnou snáze.
Využít samozřejmě můžeme i paměti veřejně dostupné. Ovšem pozor, některé z nich jsou extrémně velké, a tak jejich zpracování může trvat několik dní a běžný počítač na ně nemusí stačit. Paměti také samozřejmě můžeme vytvořit z hotových překladů zarovnáváním, ale zatímco při ručním vyhledávání v pamětech občas nějaká ta špatně spárovaná věta příliš nevadí, překladač může každý takový segment zmást a významně zhoršit kvalitu jeho výstupu.
Při zpracování pamětí můžeme připojit terminologický glosář, který následně program bude využívat při generování překladů. Termíny v glosáři ovšem potom mají vyšší prioritu než ekvivalenty, které systém našel v pamětech. To může být u flektivních jazyků jako čeština problém, protože potom se termíny z glosáře, tedy obvykle v 1. pádě jednotného čísla, ocitnou i tam, kde má být jiný gramatický tvar a systém by jej možná bez glosáře trefil správně. Proto jsem tuto možnost nezkoušel.
Záleží na velikosti?
Podívejme se, jak vypadá výstup z programu v praxi. Program jsem „natrénoval“ na překladech textů EU (sdělení, zpráv, směrnic, nařízení apod.), a to jednak na menší paměti o velikosti 21 381 segmentů, jednak na paměti o velikosti 213 810 segmentů. (V obou případech jde o část veřejně dostupných překladových pamětí Generálního ředitelství pro překlady Evropské komise za rok 2016.) Poté jsem pomocí těchto dvou modelů (anglicky „engines“) zkusil přeložit náhodně vybraný dokument EU, konkrétně rozhodnutí 2017/899 o využívání kmitočtového pásma 470–790 MHz. Na následujícím obrázku vidíme, že na velikosti pamětí záleží.
 Obrázek. Výstup z programu Slate Desktop zobrazený v Trados Studiu 2015: překlad věty z předpisu EU (32017D0899) na základě dvou různě kvalitních modelů
Obrázek. Výstup z programu Slate Desktop zobrazený v Trados Studiu 2015: překlad věty z předpisu EU (32017D0899) na základě dvou různě kvalitních modelů
Na prvním řádku je návrh vygenerovaný na základě menší paměti, na druhém řádku návrh vygenerovaný na základě větší paměti. Pro srovnání: oficiální český překlad této věty zní: „Opatření mohou zahrnovat podmínky, které mají usnadňovat či podporovat sdílení síťové infrastruktury nebo spektra v souladu s právem Unie.“ Vidíme, že zatímco v druhém případě překlad můžeme celkem úspěšně použít k posteditaci, v prvním případě nám výstup z překladače práci tolik neusnadní.
Poměrně dobrou představu o kvalitě výsledných překladů si můžeme udělat už na základě parametrů, které program hlásí u každého jednotlivého modelu.
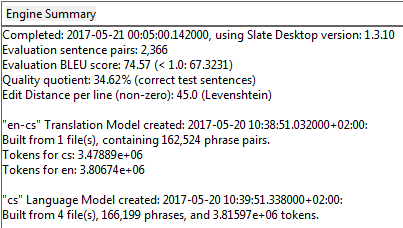
Obrázek. Parametry většího modelu – zde texty EU, před odstraněním duplicit apod. 213 810 segmentů
U modelu vytvořeného z větší paměti program uvádí, že tzv. kvocient kvality má hodnotu 34,62 %. Znamená to, že když program pomocí hotového modelu na zkoušku přeložil reprezentativní vzorek vět, 34,62 % z nich přeložil správně, tzn. dosáhl stejného znění, jaké je ve výchozí paměti. U modelu vytvořeného z menší paměti je kvocient kvality jen 1,57 %, a jak se uvádí na stránkách programu, při této hodnotě příliš dobré výsledky očekávat nemůžeme. Není divu: paměť byla podle měřítek strojového překladu velmi velmi malá.
Ze zkušeností mnoha uživatelů programu ale vyplývá, že zásada „větší je lepší“ úplně neplatí: specializované překladové paměti o velikosti 100 tisíc segmentů často nabídnou lepší řešení než obecné paměti o velikosti milionu segmentů. Některé agentury, které program používají, tak pro konkrétní zakázku ze své velké paměti vždy vyfiltrují jen relevantní segmenty (které se překládaly pro příslušného klienta, které se týkají příslušné oblasti nebo které překládala konkrétní překladatelka nebo překladatel). Z nich vytvoří model pro příslušnou zakázku a tento model poskytnou dané překladatelce či překladateli. Vrátíme-li se k naší menší testované paměti, troufnu si odhadnout, že v případě paměti omezené na jediný typ (vysoce formalizovaných a nepříliš kreativních) textů, např. na smlouvy, by smysl měla i tato velikost paměti.
Myslím, že program může být zvlášť zajímavý pro překladatele, kteří pracují v „méně obvyklých“ jazykových kombinacích, zejména v takových, které generické překladače překládají přes třetí jazyk. Zvlášť pokud pro danou kombinaci neexistuje mnoho elektronických nástrojů, především slovníků, pak i modely s nižším kvocientem kvality můžou mít pro překladatele relativně vysokou hodnotu.
Dejme se do překládání
Když Slate Desktop aktivujeme v podporovaném programu CAT, např. v SDL Trados Studiu 2015, můžeme buď text předpřeložit (tzn. strojový překlad se vloží do sloupce pro překlad), nebo si doporučení nechat nabízet průběžně. V případě Trados Studia můžeme mít zároveň aktivovaných více modelů, např. model „smlouvy“ a model „zákony“. Já jsem aktivoval výše popsaný model vytvořený z paměti o velikosti necelých 214 tisíc segmentů. Pracoval jsem v Trados Studiu 2015 a zvolil jsem možnost předpřekladu (pracoval jsem na relativně starém a nepříliš výkonném počítači, a bylo proto výhodnější celý text nejdřív předpřeložit).
Když se na přeložené věty podíváme, přísný kritik by možná řekl, že příliš nedávají smysl. V tom případě doporučuji podívat se na ně znovu a trochu jinou optikou. Často přejímáme stanovisko, které nám předkládají články v mainstreamových médiích a které stojí především na otázce „kdo s koho“ – kdy Google nahradí překladatele? Nahradí zcela člověka, nebo je úplně nepoužitelný? „Všechno, nebo nic!“ To je podle mě příliš černobílé vidění světa. Neuvažujme černobíle, ale v odstínech šedi, anebo ještě lépe v barvách. Neptejme se, jestli stroj nahradí člověka, ale jak člověku může pomoci, jak mu může usnadnit práci a jak může zvýšit kvalitu jeho práce. Uvažujme o tom, kdy je dobré využít výstup z překladače jako polotovar, který dál opracujeme ke své spokojenosti. Co v dané situaci přestavuje větší úsilí: upravit výstup z překladače, nebo celou větu přeložit a napsat tradičním způsobem? A jaké jsou s tím spojeny nástrahy a nebezpečí?
 Obrázek. Ukázka výstupu ze Slate Desktopu (v SDL Trados Studiu 2015): předpis EU 32017D0899. Segmenty jsou označeny značkou „AT“, tj. automatický překlad. Celý text vyexportovaný do tabulky najdete tady.
Obrázek. Ukázka výstupu ze Slate Desktopu (v SDL Trados Studiu 2015): předpis EU 32017D0899. Segmenty jsou označeny značkou „AT“, tj. automatický překlad. Celý text vyexportovaný do tabulky najdete tady.
Když se podíváme na návrhy Slate Desktopu touto optikou, zjistíme, že na některá slova překladatel vůbec nemusí sáhnout. Mnohdy to jsou navíc řešení, která by ho možná okamžitě nenapadla a chvíli by je musel hledat. U dalších slov stačí opravit koncovky a občas je třeba změnit slovosled. Jindy překladatel navrhované řešení nepoužije, návrh ho ale může navést správným směrem. V každém případě samozřejmě musí navrhovaný překlad velmi pozorně srovnat s originálem a ledacos ověřit (v tomto konkrétním případě musí ověřovat v relevantních předpisech, v terminologické databázi a v pravidlech pro úpravu dokumentů, to by ale dělal tak jako tak). Zkrátka musí udělat vše, co si žádá posteditace. I kdyby ale bylo použitelných jen 25 % nebo třeba 10 % všech návrhů, i to by překladateli výrazně usnadnilo práci a zvýšilo produktivitu. Kolik hodin nebo dní ušetří při překladu padesátistránkového překladu?
Někomu možná víc vyhovuje, když si návrhy nechá zobrazit v samostatném okně jen pro inspiraci a své řešení vpisuje do okénka pro překlad sám (konkrétně v Trados Studiu navíc našeptavač AutoSuggest nabízí i slova a fráze z automaticky vygenerovaného překladu). A někdo možná strojový překlad z různých důvodů zavrhne úplně. Tak jako u ostatních tipů a triků doporučuji, aby nikdo předem nic neodmítal a vyzkoušel si, co mu vyhovuje a co ne. V tomto případě to platí dvojnásob, protože u některých typů textů se program osvědčí, u jiných ne. Demoverze programu Slate Desktop prozatím k dispozici není, ale pokud si program zakoupíte a nebude vám vyhovovat, do 30 dnů si můžete nechat vrátit peníze.
Možná vás napadá otázka: „A co neuronový překlad?“ Neuronový překlad je sice horké téma, ale pro desktopové aplikace prozatím nepřichází v úvahu, protože vyžaduje výkonné grafické procesory (GPU) a ty jsou – i díky tomu, že počítačoví hráči jsou za grafické karty ochotni dát opravdu hodně – zatím velmi nákladné. Na neuronový strojový překlad (NMT) běžící přímo v našem počítači si tedy budeme muset ještě chvíli počkat. Nevadí – klasický strojový překlad (tedy tzv. frázový strojový překlad) nám má stále co nabídnout. Navíc mnozí uživatelé strojového překladu říkají, že jim u Překladače Google víc vyhovoval „klasický“ frázový překlad, ve kterém sice haprovala gramatika, ale významové úlety nebyly tak strašné jako někdy u neuronového překladu.
Power to the people
I když jsem možná program netestoval na nejvhodnějších pamětech a textech, zalíbil se mi. U testovaných textů nabízel Slate Desktop řešení, která mohla posloužit jako polotovar k dalšímu opracování a šetřil tak mnoho času – přiznám se, že když jsem ho poprvé použil v ostrém provozu, přímo jsem přímo žasl, o kolik víc stran jsem díky němu za jeden den přeložil. Udělám si proto pořádek v překladových pamětech a na některé druhy textů program začnu používat pravidelně. Slate Desktop bych doporučil každému, kdo překládá větší množství odborných nebo úředních textů a má dostatek překladových pamětí. Myslím, že učiněným požehnáním může být pro překladatele právnických a finančních textů nebo například patentů. Při dostatečném množství dat ale poslouží i mnoha dalším překladatelům.
Velmi mě oslovila i celková filozofie tvůrců programu: za rozumnou cenu dávají překladatelům k dispozici velmi mocný nástroj a tím posilují jejich pozice. Některé jazykové technologie totiž často už ze své podstaty nahrávají velkým hráčům a překladatelé se čím dál tím víc ocitají v pozici námezdní síly. Vstupujeme do éry velkých dat, kdy má konkurenční výhodu ten, kdo má velké množství relevantních a systematicky spravovaných dat. Ten potom také může investovat do dalšího rozvoje včetně strojového překladu. I kvůli přechodu na cloudové technologie pak spolupráce mezi překladatelem a agenturou často vypadá tak, že překladatel dává agentuře výsledky své práce v podobě pamětí, ale agentura může jeho přístup k systému a pamětem omezit jen na dobu, kdy pracuje na konkrétní zakázce. Agentura navíc někdy překladateli zakazuje, aby si odvedenou práci nechal uloženou v počítači. Překladatel se tak stává mnohem více nahraditelným než v minulosti.
Díky programu Slate Desktop teď můžou novými způsoby využívat svá data i překladatelé. Program jim současně ukazuje, jakou hodnotu mají kvalitní překladové paměti. K posílení pozic překladatelů může vést i promyšlené sdružování překladatelů a jejich dat, ať už jde o paměti, terminologické databáze nebo glosáře. Je na nás, jestli na přílivovou vlnu moderních technologií naskočíme, nebo se jí necháme smést.
Dostupné verze programu Slate Desktop (podrobněji zde)
- Starter – 2 jazyky, 1 počítač, podpora 30 dnů – 269 USD
- Desktop – neomezený počet jazyků, 2 počítače, neomezená podpora – 549 USD
- Toolkit – opensourceové komponenty programu – zdarma
- Připravují se další verze, mj. Trial a Connect (pouze konektor pro CAT nástroje, který umožní používat vytvořené modely)







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Neumí to v podstatě to, co nabízí Google Translator Toolkit?
Ano a ne. Slate Desktop (SD) se svou funkcí podobá Překladači Google (ze kterého bere návrhy překladových řešení i Toolkit), rozdíl je ale v tom, že v případě SD nedáváte text žádné třetí straně – zůstává ve vašem počítači, takže pomocí SD můžete překládat i citlivé texty, které váš stroj nesmí opustit (smlouvy, které to vyžadují, dnes překladatel podepisuje zcela běžně). Navíc se SD naučí překládat na základě vašich překladů, takže při dostatečně velkém množství „trénovacích“ dat dává řešení šitá na míru.
Každý překladatel, který používá Toolkit, si také musí odpovědět na otázku, jestli chce svou prací potenciálně přispívat k lepší kvalitě výstupů z Googlu a možná si tak podřezávat větev, na které sedí. Když pracujete ve svém počítači a chytře využíváte svá data, zlepšujete svou konkurenční výhodu. Když pracujete v Toolkitu/Překladači Google, s velkou pravděpodobností zlepšujete konkurenční výhodu Googlu.
Jakou verzi jste používal při testování?
Používal jsem verzi 1.3.10.
Hmmm… když jsem porovnal vaše výsledky ze Slatu s Googlem, jsou o slušné poznání horší. Rozhodně by mne to nepřesvědčilo, abych do toho těch 10 nebo kolik tisíc vrazil. Ale fakt je, že eurobláboly Google umí velmi dobře, takže možná by byl poměr sil u jiného textu jiný….
Přemýšlel jsem taky, že to vyzkouším, ale odradila mne absence trialu. Neradu kupuju zajíce v pytli, zvlášť takhle drahého.
Martin Janda
Ono jde hlavně o velikost dat, na kterých se model natrénuje, a v případě mého experimentu těch dat nebylo zas tak moc. Google je samozřejmě natrénovaný na mnohem větším objemu textů, takže by bylo víc fér srovnávat Překladač Google s ukázkou systému Moses (tvoří jádro Slatu) na stránkách ÚFALu (myslím, že trénovací korpus měl asi 0,5 mld. slov na každé straně). Trial Slatu možná prý časem bude a vývojář programu mi potvrdil, že skutečně platí záruka vrácení peněz bez udání důvodu.
Fér z pohledu Slatu možná jo, fér z pohledu překladatele nikoli. Porovnávám s nejlepšími ostatními zdroji, které mám, ne se zdroji schválně špatnými. Navíc, pokud jsem to z té analýzy nahoře i od Tomáše Jinovatky (Hoara) správně pochopil, větší databáze neznamená automaticky lepší výsledky, protože už nejpíš nebude tak specializovaná. OK, počkám si na ten trial – moc jsem nepochopil, proč ho vlastně nenabízejí – ale po téhle ukázce to vidím dost skepticky. Nejspíš zůstanu u diktování…
Demo Moses na stránkách ÚFAL MF UK rozhodně není „schválně špatný“. Moses je v oblasti frázového strojového překladu state-of-the-art a skutečně záleží na velikosti a kvalitě dat. Já jsem použil nejlepší data, jaká jsem použít mohl (měl jsem i lepší, specializovanější paměti, ale ty jsem kvůli smluvnímu vztahu s klienty nemohl použít) a při kvalitnějších datech by výsledky určitě byly lepší. I tak mi to u určitých textů výrazně zvyšuje produktivitu. Nikoho nepřesvědčuji, na prodeji programu nemám žádný komerční zájem. Jen jsem chtěl ukázat, co se mi osvědčilo a co by mohlo pomoct i ostatním překladatelům.
Jasně, tak jsem to až nemyslel 🙂 Chci jen říct, že pokud se bude jakýkoli překladatel rozhodovat, jestli investuje 10.000 do nějakého softwaru, bude především řešit, jestli mu to oproti veřejným a skoro bezplatným jiným zdrojům něco přinese. Podle této ukázky to tak moc nevypadá, ale jak jsem říkal, může to být otázka smolně vybraného vzorku. Až se s tím trochu zaběháte, třeba dáte do placu nějaký další vzorek a já se na něj rozhodně rád podívám.
[…] Pošta first posted this article July 4, 2017 on his blog, http://www.translatoblog.cz/prekladac-v-pocitaci/. We re-post the original article in its entirety as part of our Blogging Translator Review Program. […]
Dobrá zpráva: k dispozici je trial verze a několik dalších verzí, mj. „Connect“, která je vhodná např. pro týmy: jeden člen týmu vytvoří v plné verzi „engines“ pro ostatní členy a těm pak stačí jen tento konektor za 49 USD.
Hi everyone. Please forgive my English. I’m the guy behind Slate Desktop. I’ve browsed your comments (using Google, of course). Thank you, Miroslav, for your review. I started a promotion for all Slate products. If you go to our website and „like“ any page, our e-commerce system will automatically give you a 25% discount. Slate Desktop drops from $549 to $412, and Slate Starter reduces from $269 to $202. You can see more details here: https://www.slate.rocks/share-slate-rocks-get-25-off/