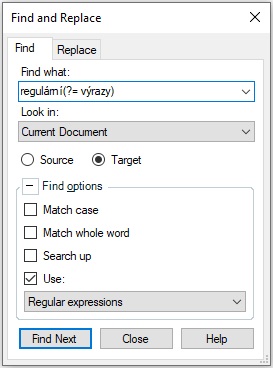
Znáte regulární výrazy neboli regexy? Jsou to speciální znaky, díky nimž můžeme v textu chytře vyhledávat a nahrazovat. Například můžeme hledat více alternativních slov nebo jejich částí najednou. Anebo určité slovo následované určitými jinými slovy. Pomocí regulárních výrazů také můžeme v nástrojích CAT lépe vyfiltrovat jen ty segmenty, které nás zajímají.
O regulárních výrazech vyšly celé knihy, a proto nabídnu jen hrst vybraných dotazů, které jsou zajímavé pro překladatele, a odkážu na dvě skvělé stránky, kde případný zájemce najde o regulárních výrazech snad úplně všechno: RexEgg a Regular-Expressions.info. Regulární výrazy využijeme v programech, které je podporují, tedy např. nástroj CAT SDL Trados Studio, textový procesor Notepad++ nebo titulkovací program SubtitleNEXT. Microsoft Word je podporuje jen částečně.
1) Nejdřív zopakuji „recept“, který už jsem nabídl v samostatném článku, a to na vyhledání obyčejných jednopísmenných slov (tzn. k, s, v, z, a, i, o, u) následovaných obyčejnou mezerou a na nahrazení pevné mezery mezerou obyčejnou
Najít: \b([aiouksvz])·
- Znakem · značím obyčejnou mezeru, tedy normálně stiskneme mezerník
- \b znamená hranici slova, tedy jeho začátek nebo konec: díky tomuto výrazu tedy nebudeme hledat slova zakončená na uvedená písmena, ale jen samostatná jednopísmenná slova
- [aiouksvz] znamená, že hledáme libovolné písmeno z uvedeného seznamu
Nahradit čím:
- Když v Tradosu budeme chtít nahradit nalezený řetězec stejným písmenem následovaným pevnou mezerou, do okénka pro nahrazení zadáme: $1°
- Znakem ° značím pevnou mezeru, kterou zadáme jako Alt+160 nebo také jako \xA0
- V jiných programech místo $1 zadáme \1
2) Druhý recept je pro toho, kdo chce naopak najít pevné mezery po dvoupísmenném a vícepísmenném slovu a tyto pevné mezery nahradit obyčejnými mezerami.
Najít: (\w{2,})\xA0
- \w znamená „písmenný znak“, neboli písmeno, číslice nebo podtržítko
- {2,} znamená dvě a více opakování předcházejícího výrazu,
- což dohromady znamená libovolný počet písmen/číslic/podtržítek
- pevnou mezeru jsme tentokrát zadali jako \xA0
Nahradit čím:
- V Tradosu zadáme: $1·
- Ve většině jiných programů zadáme: \1·
- Znakem · opět značím obyčejnou mezeru, tzn. stiskneme mezerník
- $1 respektive \1 odkazuje na obsah prvních závorek. V tomto hledání máme závorky jediné, jde tedy o výraz \w{2,}
- Neboli nalezené slovo před pevnou mezerou nahradíme týmž slovem a za něj vložíme pevnou mezeru
- Mimochodem kdybychom chtěli najít všechny tvary spojení Česká republika, můžeme zadat: Česk\w+ republi\w+
3) Třetí recept je pro toho, kdo chce nahradit desetinné tečky desetinnými čárkami (a v číslech nejsou žádné mezery).
Najít: (\d+)\.(\d+)
- \d znamená libovolnou číslici od 0 do 9
- \. znamená tečku. Zpětné lomítko je před tečkou proto, že bez něj by znamenala libovolný jeden znak
- Symbol + znamená jedno či více opakování předchozího znaku, tedy libovolný počet po sobě jdoucích číslic
Nahradit čím (Trados): $1,$2
Nahradit čím (jiné programy): \1,\2
- $1 resp. \1 odkazuje na obsah prvních závorek, $2 resp. \2 na obsah druhých závorek
4) Jak hledat více slov, více tvarů slova nebo více částí slova najednou. Hledejme například všechny tvary zájmena vy (včetně nespisovného váma).
Hledat: \b(vy|vás|vám|vámi|váma)\b
- Pomocí \b vymezíme začátek a konec slova, abychom nenašli například kávy
- Jednotlivá slova (alternativy) oddělíme svislítkem
Můžeme zadat třeba i: (horizontal|vertical) align
Najdeme jednak horizontal align, jednak vertical align
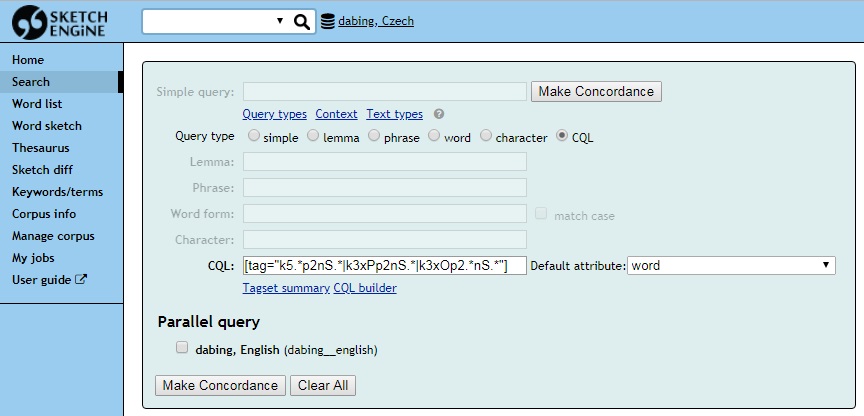
Svislítko často využijeme i ve filtru Tradosu: můžeme vyfiltrovat segmenty, které obsahují určitá slova (a často vystačíme i bez \b).
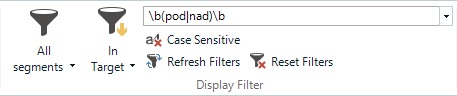
Obrázek. Filtrování v SDL Trados Studiu pomocí regulárních výrazů
5) Hledáme mezeru na začátku řádku/segmentu/titulku
Hledat: ^·
- Obyčejnou mezeru opět značím jako ·
- Můžeme ji zadat i jako \x20 – zadání potom bude znít: ^\x20
Nahradit čím:
- Do okénka nenapíšeme vůbec nic, tedy ani mezeru. Mezeru tedy nahradíme „ničím“. Toho, že bychom vymazali začátek řádky, se bát nemusíme.
Podobně můžeme pomocí stříšky najít určité slovo na konci řádku/segmentu/titulku. A kdybychom chtěli hledat naopak na konci řádku/segmentu/titulku, použijeme symbol $.

Obrázek. Hledání mezery na začátku řádků v titulkovacím programu SubtitleNEXT
6) Hledáme mezeru na konci řádku/segmentu/titulku
Hledat: ·$
- Obyčejnou mezeru opět značím jako ·
- Můžeme ji zadat i jako \x20 – zadání potom bude znít: \x20$
- Symbol $ zadáme nejsnáze jako AltGr+ů
7) Hledáme zalomení řádku („enter“) následované malým písmenem. Zalomení řádku odstraníme – tímto způsobem můžeme opravit výstup z OCR, ve kterém je věta často rozťata vejpůl. Použít můžeme například editor Notepad++.
Hledat: \R([a-ž])
Nahradit čím: \1
nebo: ·$1
- Mít zaškrtnuté Rozlišovat malá a VELKÁ písmena
- Symbolem · opět značím obyčejnou mezeru
- \R funguje jen v Notepadu++
Tuto operaci můžeme udělat i ve Wordu, ten ale regulární výrazy zapisuje trochu jinak:
Najít: ^13([a-ž])
Nahradit čím: ·\1
- Symbolem · opět značím obyčejnou mezeru
- Zaškrtneme Použít zástupné znaky
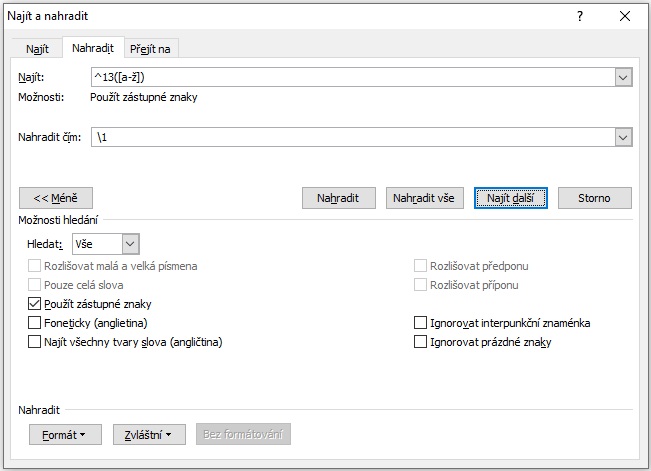
Obrázek. Odstranění zalomení řádku před malými písmeny v programu MS Word
Vysoká škola regexová
K nejpokročilejším regulárním výrazům patří takzvané lookaroundy, tedy jednak lookbehindy a lookaheady. Jak napovídají jejich názvy, jedny se v textu „dívají“ zpět a druhé dopředu. Jinými slovy, hledáme něco, co je nebo naopak není v blízkosti něčeho jiného, aniž na to něco jiného „saháme“.
Lookaroundy
- pozitivní lookbehind (před danou pozicí něco je)
- např. tree následující po apple a mezeře: (?<=apple )tree
- lookaround může obsahovat i více alternativních slov: (?<=apple|pear|plum )tree
- negativní lookbehind (před danou pozicí něco není)
- např. tree NEnásledující po apple: (?<!apple )tree
- pozitivní lookahead (po dané pozici něco je)
- apple následované tree: apple(?= tree)
- negativní lookahead (po dané pozici něco není)
- apple NEnásledované tree: apple(?! tree)
Možná si říkáte, proč místo pozitivních lookaroundů rovnou nezadat třeba spojení slov apple tree. Ano, někdy to stačí a je to mnohem jednodušší. Ale pokud zadáte dotaz s lookaroundem, na obsah lookaroundu vůbec nesaháte, a proto můžete snáze nahrazovat. Bohužel ne všechny programy lookaroundy podporují anebo je podporují jen částečně: třeba v SDL Trados Studiu není problém filtrovat, ale při nahrazování s lookaroundy nastává problém.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}